
Introducción
En Dumbstruck: A Cultural History of Ventriloquism, Steven Connor acuña la noción de cuerpo vocálico para referirse a cómo, del mismo modo que los cuerpos pueden producir voces, las voces, a su vez, producen un tipo de cuerpos que se sostienen únicamente en las operaciones de la propia voz y su sonido.
Este fenómeno se aprecia, por ejemplo, en el sexo telefónico, donde el cuerpo que emite la voz y el cuerpo que la voz produce en nosotros al escucharla no son necesariamente el mismo.
Parafraseando a Maite Garbayo Maeztu diríamos que las voces «citan cuerpos» y citar es ‘traer aquí’, ‘hacer aparecer’ y ‘dar presencia’.
Los cuerpos que las voces traen y hacen aparecer, al citarlos, no son cuerpos generales, sino que lo son en su especificidad material: tensión glotal, saliva, la lengua, los conductos nasales, cavidades resonantes y pulmones bombeando aire; son también cuerpos socioculturalmente situados: género, procedencia geopolítica, clase social, estado emocional, etc.
Esto sucede así también para las voces técnicamente producidas, reproducidas y manipuladas, como las grabaciones de voz, las voces procesadas y las voces sintéticas. Todas estas voces citan también cuerpos. Cuerpos, en este caso, híbridos con las tecnologías que los hacen posibles.
Al oír, por ejemplo, las voces procesadas de estilos de música popular contemporánea, oímos cuerpos vestidos de materialidad tecnológica. Cuerpos, algunos, difíciles de imaginar. Otros cuerpos, cuerpos posibles de cuerpo presente.
La presencia, en el aquí y el ahora, del cuerpo vocálico, tecnológicamente hibridado, que esas voces hacen aparecer es algo del orden de la performance que pide ser explorado desde el performance art.
¿Qué es?
Podemos trabajar en performance a partir de voces y, en particular, a partir de voces grabadas, procesadas o incluso voces sintéticas. Podemos hacerlo y esperar que las voces hagan aparecer la presencia particular de los cuerpos vocálicos que producen.
Esto abre una vía, muy rica en posibilidades, para trabajar performances desde voz. Podemos hacerlo con las voces sintéticas de móviles y ordenadores personales, con pedales o software de efectos de voz, con grabaciones de voz mediante nuestros propios móviles u otros programas que permiten manipular, cambiando la velocidad, troceando y procesando, con efectos, esas voces.
Podemos también situar esas voces en el espacio, disponerlas en el tiempo. Ponerlas en relación entre ellas y con una posible audiencia.
Podemos incluso explorar las genealogías técnicas de estas voces, la historia y acontecimientos que han hecho posible su existencia y las cargan de sentido, más allá de lo que dicen o cómo lo dicen.
Veremos una serie de trabajos que hacen precisamente esto y que nos ofrecen un catálogo de ejemplos para trabajar con estas voces en performance.
Ejemplos
The VODER (1939)

Fotografía de The VODER
Fuente: https://talkingmachinesproject.files.wordpress.com/2020/09/pk-001a.jpg?w=802
El VODER fue el primer sintetizador electrónico de voz de la historia, producido por Bell Laboratories, la empresa que fundó Alexander Graham Bell para explotar la patente comercial del primer teléfono (https://www.youtube.com/watch?v=0rAyrmm7vv0&t=13s).
El VODER, acrónimo para voice operation demonstrator, se creó para demostrar una tecnología que se sigue utilizando para descomponer la voz y comprimirla antes de transmitirse por canales telefónicos.
EL VODER no pertenece al ámbito del arte, ni nos ofrece una performance al uso, sin embargo, en tanto su función era la de demostración tecnológica, Bell Laboratories desarrolló una serie de presentaciones públicas en diversas de las llamadas exposiciones universales, que ofrecen un ejemplo interesante para hablar de voz sintética y performance.
A diferencia de los motores actuales de síntesis de voz, que suelen producir voz a partir de texto, el VODER requería de la manipulación habilidosa de una serie de controles físicos complejos: once teclas principales, tres teclas laterales adicionales, una barra bajo la muñeca y un pedal. Estos controles debían ser manipulados con precisión y sincrónicamente para producir cada uno de los sonidos y tonos que forman cada palabra.
Para manejar el VODER, Bell Laboratories reclutó y entrenó durante algo más de un año a un grupo de telefonistas que ya trabajaban para la compañía recibiendo llamadas, conectando, desconectando y volviendo a conectar cables a través de los altos paneles de las centrales telefónicas de la época.
Durante sus entrenamientos, las telefonistas seguían un manual y hablaban entre ellas utilizando la voz masculina del VODER.
La puesta en escena del aparato consistía en un podio, sobre el que se situaba un módulo donde se sentaba la telefonista operadora, la espalda recta, las manos sobre el teclado del VODER. Tras ella, en la pared se alzaba una gran máscara de cuya boca abierta surgían ondas sonoras y que quería representar al VODER mismo y su voz. Junto a la operadora, un presentador, de pie, frente a un micrófono, guiaba la demostración, haciendo preguntas y dando instrucciones a la operadora, quien articulaba sus respuestas por medio de la voz del VODER.
Además de ocupar un lugar central en la puesta en escena del VODER, la telefonista aparecía en todos sus materiales de promoción, así como en algunos diagramas técnicos. Podemos leer una relación entre la voz del VODER y el cuerpo silencioso de la telefonista. Un cuerpo que traía consigo la disciplina férrea del trabajo propio de las telefonistas: largas horas sentadas en batería frente a los paneles conmutadores de la central telefónica, sometidas a un control de velocidad y eficiencia cuasi militar. Adicionalmente, para conseguir el trabajo, eran medidas, sus brazos, sus piernas; y si quedaban embarazadas eran despedidas.
Las telefonistas traen entonces una historia, una carga corporal situada, propia de la experiencia de estas mujeres, que a su vez carga de corporalidad la performance The VODER. Las operadoras funcionan como un potente cuerpo delegado que, como en una posesión, canaliza y permite que la voz del VODER pueda acceder al acontecimiento mismo de la performance.
De forma significativa, es tan solo en las demostraciones radiofónicas del VODER que se conservan donde, quizá porque el cuerpo de la operadora es invisible, se le pide que hable. Al hablar le oímos describir cómo para producir voz, ha de producir cuerpo, ha de producir una serie de movimientos sincrónicos en sucesión, adquiridos en largas sesiones de entrenamiento corporal.
Frente a la persuasiva idea de que las voces radiofónicas, grabadas y en particular las sintéticas no tienen cuerpo; el caso del VODER nos ofrece un modelo de producción sintética de voz intensamente corporal anclada a un cuerpo con género, social, cultural y políticamente situado.
Siri Landgren, The voice is false (2013)

Fotografía de The voice is false, de Siri Landgren (2013)
Fuente: https://i.vimeocdn.com/video/545609938-45cde01701f0db5b5ea6c5c971f8259904346fc014ed80e22b72b51934813960-d?mw=1700&mh=956&q=70
The voice is false es una conferencia performance que explora las relaciones entre determinadas prácticas vocales y determinados discursos de género. (https://sirilandgren.se/)
Como su título sugiere, Landgren se centra en la atribución de «falsedad» a algunas voces y, por tanto, a las expectativas de «verdad» esencial y profunda que solemos proyectar sobre las voces en general, en particular en relación con el género.
Durante la conferencia performance, la artista hace uso de una serie de efectos de voz, como el actualmente muy extendido Auto-Tune, estableciendo un paralelismo entre la «falsedad» o «antinaturalidad» de género, y la asociada con la manipulación digital y electrónica de la voz.
La posición específica desde la que Landgren construye y ejecuta esta performance es la de mujer trans. Y es en relación con esta posición y vivencia que debemos entender los discursos en torno a la falsedad y anti-naturalidad de género en la voz, tal y como ella los despliega en The voice is false.
Landgren establece una genealogía de nociones sobre la voz: falsa, copia, reproducción, inauténtica, artificial, sintética, forzada, híbrida, impura, mulata, criolla, incompleta, mentirosa, deshonesta, etc., que en sí misma sirve para establecer esa relación entre la posición de una mujer trans (denostada como falsa mujer, artificial, inauténtica) y las tecnologías de manipulación, producción y reproducción de la voz.
Adicionalmente, la artista narra una genealogía de casos, entre los que destacaremos la historia de la técnica del falsetto en bel canto, así como la de los castrati, quienes por haber conservado la voz previa a su transformación en la adolescencia, no requerían de dicha técnica. Landgren habla también del efecto Auto-Tune y, en particular, del rol que este efecto tiene en la construcción pública de la voz del cantante T-Pain.
En términos generales, The voice is false se alinea con discursos que consideran al género no como un atributo biológico, sino como una técnica social y cultural para la producción de los cuerpos.
Holly Herndon, Holly + (2021 – en curso)

Fotografía de «Holly +», de Holly Herndon (2021 – en curso)
Fuente: https://holly.mirror.xyz/_next/image?url=https%3A%2F%2Fimages.mirror-media.xyz%2Fpublication-images%2Fefd810c5-a752-4c7e-b32f-1208a4f9a5e5.jpg&w=1920&q=90
Holly Herndon es una reconocida artista, compositora y cantante, así como doctorada por el Center for Computer Research in Music and Acoustics de la Universidad de Stanford, con una tesis sobre la interacción entre el aprendizaje automático (machine learning) y la voz, y las implicaciones de esta tecnología para la propiedad intelectual y la soberanía vocal (https://holly.plus/).
Su trabajo musical se caracteriza por la experimentación con herramientas digitales de manipulación vocal en el contexto de composiciones electrónicas.
Recientemente, Herndon ha hecho público su proyecto Holly +, una herramienta de producción musical desarrollada a partir de un modelo de su propia voz procesada, generado utilizando técnicas de aprendizaje automático e inteligencia artificial.
El funcionamiento es simple, cualquier persona puede subir un archivo sonoro al sitio web del proyecto, los tonos y ritmos de este archivo se combinan con las texturas de la voz procesada de Holly Herndon, lo que da como resultado un híbrido entre el sonido subido y las características e idiosincrasia de la voz de Herndon, tal y como la conocemos por su música.
Adicionalmente, Herndon plantea un modelo de propiedad distribuida para este doble digital de su voz, que ella denomina organización autónoma descentralizada, o DAO. Bajo este modelo, grosso modo, las distintas personas propietarias de su voz digital pueden aprobar determinados usos artísticos de esta voz y, en caso de que estos usos produzcan dinero, este dinero se reparte en distintas proporciones entre las personas que forman parte del DAO, incluyendo la propia Herndon.
El contexto en el que Herndon emplaza su proyecto es el de la emergencia actual de la capacidad técnica para producir clones autónomos de la voz de personas específicas, incluyendo las voces de cantantes o personalidades públicas. Estos clones serán eventualmente indistinguibles de las voces originales. Y aunque se trata de voces sintéticas, estas podrán hablar y cantar, sin necesidad de que intervenga la persona en quien se origina la voz: son autónomas, en este sentido.
Esta autonomía a su vez plantea una problemática en torno a la propiedad, en términos legales y éticos, de nuestras voces. Esto es particularmente interesante, ya que la voz siempre se ha entendido como algo único y profundamente atado al centro de la verdad esencial de las personas. Por ejemplo, como vemos en The voice is false, de Siri Landgren, atado a la verdad de género de las personas.
Una voz «rara», como la de las personas con parálisis cerebral parcial, se asocia con un «yo» profundo igualmente «raro». La carencia de voz (oral), como en las personas sordas, se ha asociado también históricamente con la carencia de humanidad o con una humanidad «disminuida» o «en falta».
En este sentido, la autonomía de estas voces y los modelos de propiedad distribuida de las mismas ponen en crisis y cuestionan esta asociación entre voz y verdad, y entre nuestra voz y las profundidades esenciales de lo que somos y quiénes somos.
Holly +, entendido como performance, es una extensión técnica y distribuida de la voz de Herndon, de la propiedad de esta voz y de su materialidad. Una performance entendida como red de agentes y acciones sosteniendo, en el tiempo, la particular presencia y cuerpos vocálicos de la voz procesada de Holly Herndon.
Human Microphone
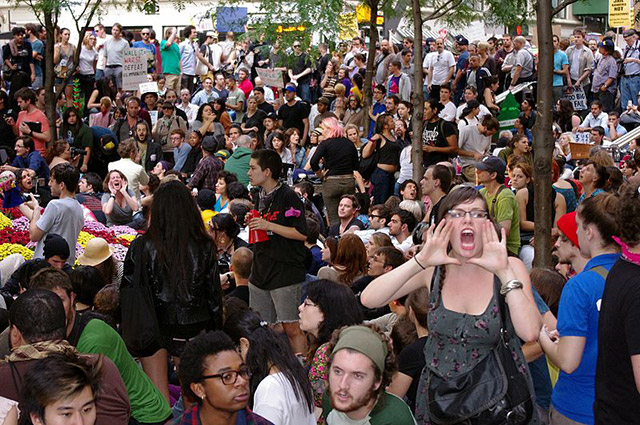
Fotografía de Human Microphone
Fuente: https://commons.wikimedia.org/wiki/File:Day_14_Occupy_Wall_Street_September_30_2011_Shankbone_2.JPG
Durante las ocupaciones del espacio público que sucedieron en 2011 en Estados Unidos bajo el nombre de Occupy Wall Street y, en particular, durante la ocupación de Zuccotti Park en Nueva York, sucedió algo interesante en relación con la voz y la tecnología (https://www.youtube.com/watch?v=tvJqLo_o7AM).
Las personas participantes de las multitudinarias asambleas que se daban en el parque se encontraron con un problema para escucharse las unas a las otras derivado de la prohibición sobre el uso de aparatos de amplificación de voz, como micrófonos, altavoces y megáfonos.
Frente a la imposibilidad de utilizar medios electrónicos de amplificación de voz, recurrieron a una técnica vocal colectiva que denominaron human microphone (‘micrófono humano’).
La técnica consiste en que la persona que posee la palabra en ese momento de la asamblea dice tan solo una o dos frases que son, a continuación, repetidas colectivamente por todas aquellas personas que las han oído.
Esta primera repetición colectiva alcanza a un grupo de gente mayor que, a su vez, las repite colectivamente, y así progresivamente, como una suerte de eco viajero, hasta que todas las personas presentes en la asamblea han escuchado esas frases.
Entonces el parlante original dice dos frases más y el proceso se repite una y otra vez, frase tras frase, repetición colectiva tras repetición colectiva, hasta que termina su intervención y pasa la palabra a otra participante.
Lo primero que llama la atención sobre el «micrófono humano» es su nombre. Ante la ausencia de tecnología, una técnica basada exclusivamente en voces de carne recibe el nombre de un dispositivo de amplificación, el micrófono. Hay una lectura explícita y difícil de no hacer sobre esto: las tecnologías de la voz están incluso cuando no están.
Esto es extensible a todas las tecnologías de producción, reproducción y manipulación de la voz. Estas ya están en la forma en que sabemos que es posible producir nuestras voces y en la forma en que hemos aprendido a escuchar nuestras voces.
El «micrófono humano» es también una técnica que permite pasar la voz de otra persona por el propio cuerpo y por la propia voz. Hacer de su voz mi voz, oírla vibrando a través de los huesos de mi mandíbula y cráneo, oyéndola vibrar por medio de los cuerpos de las personas que me rodean.
Siguiendo con una lectura en clave tecnológica, el «micrófono humano» nos convierte también en una suerte de subwoofers humanos, vibrando individual y colectivamente al son de nuestras voces.
En tercer lugar, el «micrófono humano» se basa de forma decisiva en un fenómeno, el eco. No solo se repite, colectivamente, la primera voz, sino que esta repetición viaja a través del espacio y a través de grandes grupos de voces-cuerpo, con base en sucesivas repeticiones, hasta alcanzar los límites de la asamblea.
La metáfora técnica del eco es el efecto llamado delay (‘retraso’). Este efecto funciona con base en dos valores principales, por un lado, el tiempo de retraso, es decir, el tiempo que pasará hasta que oigamos el eco de nuestra voz; y, por otro lado, la cantidad de retroalimentación. Es decir, cuánto de ese primer eco vuelve a introducirse de nuevo en el efecto delay, recibiendo a su vez otro eco y así sucesivamente. Cuando el valor de retroalimentación es muy alto, todos los ecos reciben sucesivos ecos y todos esos segundos ecos reciben también un eco, de forma que el sonido de la voz crece exponencialmente hasta convertirse en una exaltada y ruidosa masa sonora.
En este sentido el «micrófono humano» funciona como un gran efecto delay, donde las voces se repiten colectivamente una y otra vez, una y otra vez, aumenta en la intensidad de la asamblea y de la ocupación del espacio público y amenaza con desbordar nuestras voces y nuestros cuerpos.
Referencias
Borkowski, A. (15 de mayo, 2014). «Song Of The Digital Flesh: Vocal Manipulation & Our Cyborg Selves». The Quietus. <https://thequietus.com/articles/15223-vocal-manipulation-holly-herndon-burial-katie-gately?fbclid=IwAR1U_co4_SC5pOi6vf_VfPBjFvCqkeJ5yX4cyWNiSPYSq-kL-X25eOP-a64>
Milner, G. (2010). Perfecting sound forever: An aural history of recorded music (1ª edición). Faber and Faber.
Young, M. (2015). Singing the body electric: The human voice and sound technology. Ashgate.