
Introducció
A Dumbstruck. A Cultural History of Ventriloquism, Steven Connor encunya la noció de cos vocàlic per referir-se a com, de la mateixa manera que els cossos poden produir veus, les veus, al seu torn, produeixen un tipus de cossos que se sostenen únicament en les operacions de la mateixa veu i el seu so.
Aquest fenomen s’aprecia, per exemple, al sexe telefònic, en què el cos que emet la veu i el cos que la veu produeix en nosaltres en escoltar-la no són necessàriament el mateix.
Parafrasejant Maite Garbayo Maeztu, diríem que les veus «citen cossos» i citar és ‘portar aquí’, ‘fer aparèixer’ i ‘donar presència’.
Els cossos que les veus porten i fan aparèixer, en citar-los, no són cossos generals, sinó que ho són en la seva especificitat material: tensió glotal, saliva, la llengua, els conductes nasals, cavitats ressonants i pulmons bombant aire; també són cossos socioculturalment situats: gènere, procedència geopolítica, classe social, estat emocional, etc.
Això també passa així per a les veus tècnicament produïdes, reproduïdes i manipulades, com els enregistraments de veu, les veus processades i les veus sintètiques. Totes aquestes veus també citen cossos. Cossos, en aquest cas, híbrids amb les tecnologies que els fan possibles.
En sentir, per exemple, les veus processades d’estils de música popular contemporània, sentim cossos vestits de materialitat tecnològica. Cossos, alguns, difícils d’imaginar. Altres cossos, cossos possibles de cos present.
La presència, en l’aquí i l’ara, del cos vocàlic, tecnològicament hibridat, que aquestes veus fan aparèixer és un fet de l’ordre de la performance que demana que s’explori des del performance art.
Què és?
Podem treballar en performance a partir de veus i, en particular, a partir de veus gravades, processades o, fins i tot, veus sintètiques. Ho podem fer i esperar que les veus facin aparèixer la presència particular dels cossos vocàlics que produeixen.
Això obre una via, molt rica en possibilitats, per treballar performances des de la veu. Ho podem fer amb les veus sintètiques de mòbils i ordinadors personals, amb pedals o programari d’efectes de veu, amb enregistraments de veu mitjançant els nostres propis mòbils o altres programes que permeten manipular, canviant la velocitat, trossejant i processant, amb efectes aquestes veus.
També podem situar aquestes veus en l’espai i disposar-les en el temps. Posar-les en relació entre elles i amb una possible audiència.
Podem, fins i tot, explorar les genealogies tècniques d’aquestes veus: la història i els esdeveniments que n’han fet possible l’existència i les carreguen de sentit, més enllà del que diuen o com ho diuen.
Veurem una sèrie de treballs que fan precisament això i que ens ofereixen un catàleg d’exemples per treballar amb aquestes veus en performance.
Exemples
The VODER (1939)

Fotografia de The VODER
Font: https://talkingmachinesproject.files.wordpress.com/2020/09/pk-001a.jpg?w=802
El VODER va ser el primer sintetitzador electrònic de veu de la història, produït per Bell Laboratories, l’empresa que va fundar Alexander Graham Bell per explotar la patent comercial del primer telèfon (https://www.youtube.com/watch?v=0rayrmm7vv0&t=13s).
El VODER, acrònim per a voice operation demonstrator, es va crear per demostrar una tecnologia que es continua utilitzant per descompondre la veu i comprimir-la abans de transmetre-la per canals telefònics.
El VODER no pertany a l’àmbit de l’art, ni ens ofereix una performance en ús. No obstant això, en tant que la seva funció era la de demostració tecnològica, Bell Laboratories va desenvolupar una sèrie de presentacions públiques en diverses de les anomenades exposicions universals, que ofereixen un exemple interessant per parlar de veu sintètica i performance.
A diferència dels motors actuals de síntesi de veu, que solen produir veu a partir de text, el VODER requeria la manipulació hàbil d’una sèrie de controls físics complexos: onze tecles principals, tres tecles laterals addicionals, una barra sota el canell i un pedal. Aquests controls havien de ser manipulats amb precisió i sincrònicament per produir cadascun dels sons i tons que formen cada paraula.
Per manejar el VODER, Bell Laboratories va reclutar i va entrenar durant una mica més d’un any un grup de telefonistes que ja treballaven per a la companyia rebent trucades, connectant, desconnectant i tornant a connectar cables a través dels alts panells de les centrals telefòniques de l’època.
Durant els entrenaments, les telefonistes seguien un manual i parlaven entre elles utilitzant la veu masculina del VODER.
La posada en escena de l’aparell consistia en un podi, sobre el qual se situava un mòdul on s’asseia la telefonista operadora, amb l’esquena recta i les mans sobre el teclat del VODER. Darrere d’ella, a la paret s’alçava una gran màscara de la boca oberta de la qual sorgien ones sonores i que volia representar el VODER mateix i la seva veu. Al costat de l’operadora, un presentador, dret, davant d’un micròfon, guiava la demostració, fent preguntes i donant instruccions a l’operadora, qui articulava les seves respostes per mitjà de la veu del VODER.
A més d’ocupar un lloc central a la posada en escena del VODER, la telefonista apareixia en tots els materials de promoció, així com en alguns diagrames tècnics. Podem llegir una relació entre la veu del VODER i el cos silenciós de la telefonista. Un cos que duia a sobre la disciplina fèrria de la feina pròpia de les telefonistes: llargues hores assegudes en bateria davant dels panells commutadors de la central telefònica, sotmeses a un control de velocitat i eficiència quasi militar. Addicionalment, per aconseguir la feina, se’ls mesuraven els braços i les cames, i si quedaven embarassades, eren acomiadades.
Les telefonistes porten aleshores una història, una càrrega corporal situada, pròpia de l’experiència d’aquestes dones, que al seu torn carrega de corporalitat la performance The VODER. Les operadores funcionen com un potent cos delegat que, com en una possessió, canalitza i permet que la veu del VODER pugui accedir a l’esdeveniment mateix de la performance.
De manera significativa, tan sols en les demostracions radiofòniques del VODER que es conserven, potser perquè el cos de l’operadora és invisible, se li demana que parli. En parlar, li sentim descriure com per produir veu, ha de produir cos, ha de produir una sèrie de moviments sincrònics en successió, adquirits en llargues sessions d’entrenament corporal.
Enfront de la persuasiva idea que les veus radiofòniques, gravades i, en particular, les sintètiques no tenen cos, el cas del VODER ens ofereix un model de producció sintètica de veu intensament corporal ancorada a un cos amb gènere, socialment, culturalment i políticament situat.
Siri Landgren, The voice is false (2013)

Fotografia de The voice is false, de Siri Landgren (2013)
Font: https://i.vimeocdn.com/video/545609938-45cde01701f0db5b5ea6c5c971f8259904346fc014ed80e22b72b51934813960-d?mw=1700&mh=956&q=70
The voice is false és una conferència performance que explora les relacions entre determinades pràctiques vocals i determinats discursos de gènere (vegeu a https://sirilandgren.se/251/).
Com suggereix el títol, Landgren se centra en l’atribució de «falsedat» a algunes veus i, per tant, a les expectatives de «veritat» essencial i profunda que solem projectar sobre les veus en general, en particular en relació amb el gènere.
Durant la conferència performance, l’artista fa ús d’una sèrie d’efectes de veu, com l’actualment molt estès Auto-Tune, establint un paral·lelisme entre la «falsedat» o «antinaturalitat» de gènere, i l’associada amb la manipulació digital i electrònica de la veu.
La posició específica des d’on Landgren construeix i executa aquesta performance és la de dona trans. I és en relació amb aquesta posició i vivència que hem d’entendre els discursos entorn de la falsedat i anti-naturalitat de gènere en la veu, tal com ella els desplega a The voice is false.
Landgren estableix una genealogia de nocions sobre la veu: falsa, còpia, reproducció, inauténtica, artificial, sintètica, forçada, híbrida, impura, mulata, criolla, incompleta, mentidera, deshonesta, etc., que en si mateixa serveix per establir aquesta relació entre la posició d’una dona trans (injuriada com a falsa dona, artificial, inauténtica) i les tecnologies de manipulació, producció i reproducció de la veu.
Addicionalment, l’artista narra una genealogia de casos, entre els quals destacarem la història de la tècnica del falset al bel canto, així com la dels castrats, que, per haver conservat la veu prèvia a la seva transformació en l’adolescència, no requerien aquesta tècnica. Landgren també parla de l’efecte Auto-Tune i, en particular, del rol que aquest efecte té en la construcció pública de la veu del cantant T-Pain.
En termes generals, The voice is false s’alinea amb discursos que consideren el gènere no com un atribut biològic, sinó com una tècnica social i cultural per a la producció dels cossos.
Holly Herndon, Holly + (2021 – en curs)

Fotografia de Holly +, de Holly Herndon (2021 – en curs)
Font: https://holly.mirror.xyz/_next/image?url=https%3A%2F%2Fimages.mirror-media.xyz%2Fpublication-images%2Fefd810c5-a752-4c7e-b32f-1208a4f9a5e5.jpg&w=1920&q=90
Holly Herndon és una reconeguda artista, compositora i cantant, així com doctorada pel Center for Computer Research in Music and Acoustics de la Universitat de Stanford, amb una tesi sobre la interacció entre l’aprenentatge automàtic (machine learning) i la veu, i les implicacions d’aquesta tecnologia per a la propietat intel·lectual i la sobirania vocal (https://holly.plus/).
El seu treball musical es caracteritza per l’experimentació amb eines digitals de manipulació vocal en el context de composicions electròniques.
Recentment, Herndon ha fet públic el seu projecte Holly +, una eina de producció musical desenvolupada a partir d’un model de la seva pròpia veu processada, generat utilitzant tècniques d’aprenentatge automàtic i intel·ligència artificial.
El funcionament és simple: qualsevol persona pot penjar un arxiu sonor al lloc web del projecte, i els tons i ritmes d’aquest arxiu es combinen amb les textures de la veu processada de Holly Herndon, i això dona com a resultat un híbrid entre el so penjat i les característiques i idiosincràsia de la veu de Herndon, tal com la coneixem per la seva música.
Addicionalment, Herndon planteja un model de propietat distribuïda per a aquest doble digital de la seva veu, que ella anomena organització autònoma descentralitzada, o DAO. Amb aquest model, grosso modo, les diferents persones propietàries de la seva veu digital poden aprovar determinats usos artístics d’aquesta veu, i en cas que aquests usos generin diners, aquests diners es reparteixen en diferents proporcions entre les persones que formen part del DAO, incloent-hi la mateixa Herndon.
El context en què Herndon situa el seu projecte és el de l’emergència actual de la capacitat tècnica per produir clons autònoms de la veu de persones específiques, incloent-hi les veus de cantants o personalitats públiques. Aquests clons seran eventualment indistingibles de les veus originals. I malgrat que es tracta de veus sintètiques, aquestes podran parlar i cantar, sense necessitat que intervingui la persona en qui s’origina la veu: són autònomes, en aquest sentit.
Aquesta autonomia, al seu torn, planteja una problemàtica entorn de la propietat, en termes legals i ètics, de les nostres veus. Això és particularment interessant, ja que la veu sempre s’ha entès com un element únic i profundament lligat al centre de la veritat essencial de les persones. Per exemple, com veiem a The voice is false, de Siri Landgren, lligat a la veritat de gènere de les persones.
Una veu «estranya», com la de les persones amb paràlisi cerebral parcial, s’associa amb un «jo» profund igualment «estrany». La manca de veu (oral), com en les persones sordes, també s’ha associat històricament amb la manca d’humanitat o amb una humanitat «disminuïda» o «en falta».
En aquest sentit, l’autonomia d’aquestes veus i els models de propietat distribuïda posen en crisi i qüestionen aquesta associació entre veu i veritat, i entre la nostra veu i les profunditats essencials de què som i qui som.
Holly +, entesa com a performance, és una extensió tècnica i distribuïda de la veu de Herndon, de la propietat d’aquesta veu i de la seva materialitat. Una performance entesa com a xarxa d’agents i accions que sostenen, en el temps, la particular presència i cossos vocàlics de la veu processada de Holly Herndon.
Human Microphone
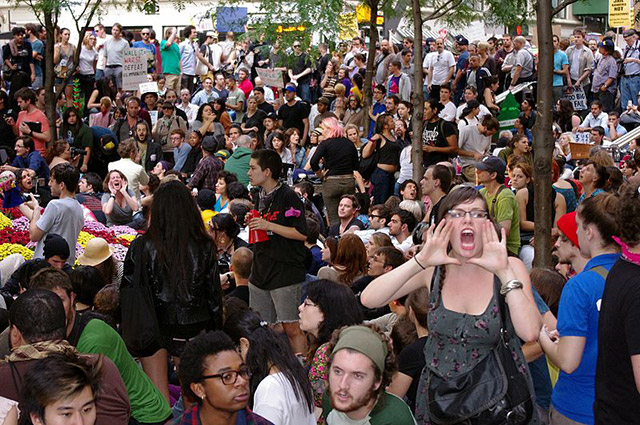
Fotografia de Human Microphone
Font: https://commons.wikimedia.org/wiki/File:Day_14_Occupy_Wall_Street_September_30_2011_Shankbone_2.JPG
Durant les ocupacions de l’espai públic que es van succeir el 2011 als Estats Units amb el nom d’Occupy Wall Street i, en particular, durant l’ocupació de Zuccotti Park, a Nova York, va passar una cosa interessant en relació amb la veu i la tecnologia (https://www.youtube.com/watch?v=tvjqlo_o7am).
Les persones participants en les multitudinàries assemblees que es donaven al parc es van trobar amb un problema per sentir-se les unes a les altres derivat de la prohibició d’usar aparells d’amplificació de veu, com ara micròfons, altaveus i megàfons.
Arran de la impossibilitat d’utilitzar mitjans electrònics d’amplificació de la veu, van recórrer a una tècnica vocal col·lectiva que van anomenar human microphone [‘micròfon humà’].
La tècnica consisteix en el fet que la persona que té la paraula en aquell moment de l’assemblea diu tan sols una o dues frases, que són, a continuació, repetides col·lectivament per totes les persones que les han sentides.
Aquesta primera repetició col·lectiva arriba a un grup de gent més gran, que, al seu torn, repeteix les frases col·lectivament, i així progressivament, com una mena d’eco viatger, fins que totes les persones presents a l’assemblea han sentit aquelles frases.
Aleshores, el parlant original diu dues frases més i el procés es repeteix una vegada i una altra, frase rere frase, repetició col·lectiva rere repetició col·lectiva, fins que acaba la seva intervenció i passa la paraula a una altra participant.
El primer que crida l’atenció sobre el «micròfon humà» és el seu nom. A causa de l’absència de tecnologia, una tècnica basada exclusivament en veus de carn rep el nom d’un dispositiu d’amplificació: el micròfon. Hi ha una lectura explícita i difícil de no fer sobre això: les tecnologies de la veu hi són fins i tot quan no hi són.
Això és extensible a totes les tecnologies de producció, reproducció i manipulació de la veu. Aquestes ja es troben en la forma en què sabem que és possible produir les nostres veus i en la forma en què hem après a escoltar les nostres veus.
El «micròfon humà» també és una tècnica que permet passar la veu d’una altra persona pel propi cos i per la pròpia veu. Fer de la seva veu la meva veu, sentir-la vibrant a través dels ossos de la meva mandíbula i crani, sentint-la vibrar per mitjà dels cossos de les persones que m’envolten.
Seguint amb una lectura en clau tecnològica, el «micròfon humà» també ens converteix en una mena de subwoofers humans, vibrant individualment i col·lectivament al so de les nostres veus.
En tercer lloc, el «micròfon humà» es basa de manera decisiva en un fenomen: l’eco. No sols es repeteix, col·lectivament, la primera veu, sinó que aquesta repetició viatja a través de l’espai i a través de grans grups de veus-cos, amb base en successives repeticions, fins a arribar als límits de l’assemblea.
La metàfora tècnica de l’eco és l’efecte anomenat delay [‘retard’]. Aquest efecte funciona amb base en dos valors principals: d’una banda, el temps de retard, és a dir, el temps que passarà fins que sentim l’eco de la nostra veu, i, de l’altra, la quantitat de retroalimentació. És a dir, quant d’aquest primer eco es torna a introduir en l’efecte delay, rebent al seu torn un altre eco i així successivament. Quan el valor de retroalimentació és molt alt, tots els ecos reben ecos successius i tots aquests segons ecos també reben un eco, de manera que el so de la veu creix exponencialment fins a convertir-se en una exaltada i sorollosa massa sonora.
En aquest sentit, el «micròfon humà» funciona com un gran efecte delay, en què les veus es repeteixen col·lectivament una vegada i una altra, una vegada i una altra; augmenta en la intensitat de l’assemblea i de l’ocupació de l’espai públic, i amenaça de desbordar les nostres veus i els nostres cossos.
Referències
Borkowski, A. (15 de maig, 2014). «Song Of The Digital Flesh: Vocal Manipulation & Our Cyborg Selves». The Quietus. <https://thequietus.com/articles/15223-vocal-manipulation-holly-herndon-burial-katie-gately?fbclid=iwar1u_co4_sc5poi6vf_vfpbjfvcqkej5yx4cywnispysq-kl-x25eop-a64>
Milner, G. (2010). Perfecting sound forever. An aural history of recorded music (1a. ed.). Faber and Faber.
Young, M. (2015). Singing the body electric. The human voice and sound technology. Ashgate.